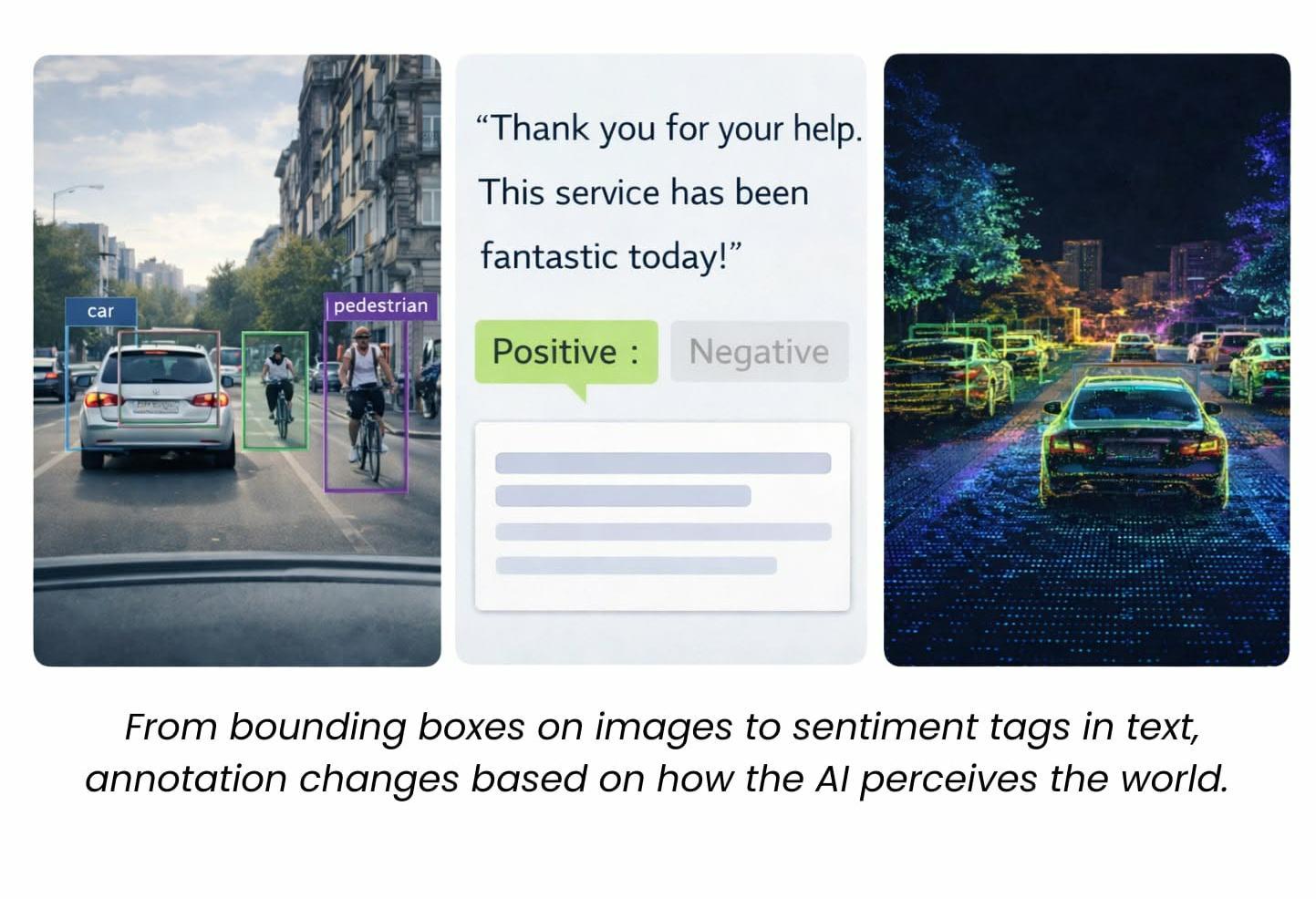
What Is Data Annotation? (Non-Tech Jargon Version)
It’s a rainy Monday morning. You’re running late, balancing a coffee in one hand and a toddler’s backpack in the other. You walk up to your car, and it unlocks automatically because it recognizes your face, even with your hood up and sunglasses on.
Feels like magic, right? But it’s not. What’s really happening is a system trained to recognize patterns, make decisions, and act in real time.
Months ago, a human sat at a computer and looked at thousands of photos of people in the rain, people in hats, and people making “I-need-coffee” faces. They drew boxes around eyes, noses, and mouthlines, telling the computer: “This is a human face, even when it’s blurry.”
That is Data Annotation.
AI operates without instinct or intuition. It behaves like a fast, obedient apprentice, responding only to what it has been trained to do. Systems behind facial recognition and chat responses rely on large volumes of labeled data, and that data ecosystem continues to grow. In 2025, the global data annotation and labeling market reached about $2.25 billion, growing roughly 30% year over year as demand for high-quality training data increased.
Why Data Annotation Matters: The “Highlighter” Metaphor
An AI model learns the way a student learns from a textbook. The difference is that the textbook is unstructured, unlabeled, and overwhelming. There are no highlighted passages, no margin notes, and no visual cues that signal importance. The model is exposed to large volumes of raw information and expected to extract meaning without guidance.
Data annotation provides that guidance. It functions as the highlighter, the annotations in the margins, and the diagrams that point to what matters and why. Labels give context to otherwise ambiguous inputs and reduce the risk of misinterpretation.

This process allows AI systems to distinguish between similar signals and make accurate judgments. It helps models determine whether an image contains a cat or a raccoon, whether a customer message expresses frustration or sarcasm, and whether a dark shape on the road is a curve or a shadow. Without labeled examples, the model lacks reference points. It does not reason through uncertainty; it defaults to probability and approximation.
Annotation transforms raw data into usable instruction. It is the difference between exposure and understanding, and it is what allows AI systems to move from pattern recognition to reliable decision-making.
Okay, So What Gets Annotated?
Annotation applies to nearly every type of data used to train modern AI systems. Different models require different forms of labeled input, depending on how they perceive and interact with the world. At RF-Tech, annotation work spans several core data formats, each serving a distinct function in model training.
Images
Visual data is annotated using techniques such as bounding boxes, segmentation masks, object classification, and keypoint labeling. These annotations help computer vision systems identify and locate people, traffic signs, medical anomalies like tumors, or items on retail shelves. Precision matters here, as even small labeling inconsistencies can affect detection accuracy at scale.
Text
Text annotation focuses on meaning, structure, and intent. Labels may include sentiment, intent classification, named entities such as people, brands, and locations, and parts of speech. This type of annotation supports applications like chatbots, legal document analysis, search relevance, and customer support automation, where understanding nuance and context is critical.
Audio
Audio annotation involves identifying speakers, tagging emotional tone, and marking specific keywords or phrases. Speaker diarization determines who is speaking and when, while emotion and tone labels help systems interpret intent beyond words alone. These annotations power voice assistants, transcription tools, and call center analytics platforms.
Video
Video annotation builds on image techniques by adding time and movement. Objects are tracked across frames, actions are labeled as they unfold, and gestures are identified in sequence. This work supports use cases in robotics, security systems, sports analysis, and motion-based user interfaces, where understanding behavior over time is essential.
LiDAR and 3D Point Clouds
Three-dimensional data from LiDAR sensors is annotated to identify objects, spatial relationships, and distances within physical environments. This format is widely used in autonomous vehicles, drones, and mapping systems that rely on accurate depth perception and spatial awareness.
Across all of these formats, annotation provides structured meaning to raw data. It turns pixels, text, sound waves, and spatial coordinates into signals that models can learn from and act on reliably.
 Why Accuracy > Speed in 2026 (and Beyond)
Why Accuracy > Speed in 2026 (and Beyond)
Annotation timelines often emphasize throughput. Large datasets create pressure to move quickly, and speed can look like progress on the surface. The problem emerges later, when models begin learning from inconsistent or incorrect labels.
Low-quality annotation introduces noise into training data. Small errors compound across large datasets, weakening model performance and increasing bias. In many cases, teams are forced to pause development and relabel data entirely, often at two to three times the original cost. What initially appeared efficient becomes a delay.
Accuracy in annotation protects downstream outcomes. Consistent labels help models learn stable patterns, while contextual understanding reduces ambiguity in edge cases. This is especially critical in high-risk applications. A single mislabeled pedestrian, traffic signal, or object boundary can undermine the reliability of an autonomous driving system. Similar risks exist in healthcare, finance, and security, where errors affect real-world decisions.
At RF-Tech, annotation work emphasizes accuracy, consistency, and context from the start. Each label is treated as an instruction the model will rely on repeatedly. Getting that instruction right matters more than how quickly it is delivered.
Real-World Examples That You’ve Probably Used
Data annotation underpins many AI-driven systems people interact with every day, often without realizing it. These applications rely on precise, context-aware labels to function safely and effectively.
🚗 Autonomous and Driver-Assistance Systems (a.k.a Self-Driving Cars)
In automotive AI, annotation extends beyond identifying objects in an image. Vehicles, bicycles, pedestrians, crosswalks, brake lights, lane markings, and weather conditions are all labeled with context about position, movement, and behavior. Models must learn how objects interact within a scene, not just that they exist. This level of detail supports decision-making in dynamic, high-risk environments.
🧠 Healthcare and Medical Imaging
In healthcare, annotated data enables AI systems to assist clinicians by highlighting areas of concern in medical images. Labels may distinguish between benign and malignant tumors, identify blood vessels, or flag early indicators of disease. Accuracy is critical here, as annotations directly influence diagnostic support tools and clinical workflows.
🛰️ Satellite and Drone Imagery
Large-scale visual data from satellites and drones is annotated to identify buildings, road networks, agricultural land, and changes to natural environments. These labels support use cases such as environmental monitoring, disaster response planning, infrastructure assessment, and logistical operations that depend on accurate spatial understanding.
🗣️Customer Support and Natural Language Processing (NLP)
Language-based systems rely on annotated text to interpret meaning beyond literal words. When a customer writes a short response like “Thanks a lot,” sentiment and intent labels help determine whether the message expresses appreciation, frustration, or sarcasm. This distinction affects routing, prioritization, and automated responses in customer support systems.
Across these examples, annotation provides the context that allows AI systems to operate reliably in real-world conditions. Without it, models struggle to interpret ambiguity, nuance, and change.
Why Human-in-the-Loop Still Matters
Human oversight remains a critical part of effective AI training. Models learn from existing patterns, but new data often introduces ambiguity that automated systems cannot reliably resolve on their own. Subtle shifts in language, unfamiliar visual scenarios, and edge cases fall outside what a model has previously seen.
Understanding context requires judgment. Sarcasm, emotional tone, cultural cues, and visual nuance are difficult to infer without human interpretation. These factors become even more important when datasets include sensitive information or high-stakes outcomes.
Human-in-the-loop workflows place experienced annotators at key decision points in the training process. Experts review uncertain cases, refine labels, and provide contextual clarity where automation reaches its limits. This approach reduces compounding errors and improves model reliability over time.
The RF-Tech Approach: Precision at Scale
RF-Tech IT Solutions works as an extension of your AI team, embedding directly into your data and model development workflows. Annotation is handled as a performance-critical process, with accuracy and consistency built in from the start.
Our work is human-verified to reduce noise and bias, tailored to your industry and labeling guidelines, and scalable across high-volume or real-time pipelines. Quality controls remain visible throughout, giving teams clear insight into how data is labeled, reviewed, and approved.
From early-stage models to enterprise-scale systems, RF-Tech supports teams that need reliable training data to move confidently into production.
Talk to RF-Tech about your next dataset
Schedule a working session to review your data, labeling requirements,
and quality thresholds before model training begins.